
پایگاهداده تصویری تصویرنت ImageNet
مقدمه
پروژه ImageNet یک پایگاه داده تصویری با ۱۴ میلیون تصویر است. در این پروژه بیش از ۳۳ هزار گروه کلمه Synset معنا دار و قابل تصویر نظیر “گربه”، “میز” و … توسط یک ساختار گرافی و سلسله مراتبی چیده شدهاند. سپس برای هر گروه کلمه تصاویر مرتبط جمع آوری شده است. این گروه کلمات خود از پروژه WordNet که یک پایگاه داده لکیسکال برای زبان انگلیسی است استخراج شده است.
۱۴ میلیون تصویر برای بیش از ۳۳ هزار گروه کلمه یک پایگاه داده جامع تصویری را ایجاد کرده است تا هر عامل هوشمندی که قابلیت یادگیری هوش بصری ( Visual Intelligence ) را داراست بتواند از این مجموعه داده جهت یادگیری هوش بصری استفاده کند. این پروژه توسط پروفسور فی فی لی در سال ۲۰۰۷ در دانشگاه استنفورد آمریکا آغاز و در سال ۲۰۱۱ توسط کرود سورسینگ داده ها از سطح اینترنت جمع آوری و سپس تفکیک داده شدند.
در ایران به دلیل محدودیتهای استفاده از پروژه ایمیج نت تصمیم به بومی سازی این پروژه با نام تصویرنت در پژوهشگاه فضای مجازی (مرکز تحقیقات مخابرات ایران) واقع در امیرآباد شمالی شد. پروژه تصویر نت شامل سه فاز زیر شد.
- فاز نخست: تحقیق و پژوهش پیرامون پروژه
- فاز دوم پیاده سازی پروژه ImageNet
- فاز نهایی بومی سازی و گسترش پروژه ImageNet با استفاده از دادگان فارسی
این پروژه توسط یک تیم ۴ نفری به مدیریت دکتر فرزاد زرگری اجرا شد که من معمار نرم افزاری و طراح پایگاه داده و طراح سایت این پروژه بودم.
فاز نخست
فاز نخست شامل بررسی ابعاد پروژه ImageNet و امکانسنجی بود. در این فاز به بررسی ساختار دادگان ImageNet و بسط پذیری آن با کلمات موجود در فرهنگ فارسی پرداخته شد.
ساختار دادگان
در ابتدا تصور میشد که ساختار دادگان به صورت یک درخت باشد. اما پس از بررسی دقیقتر متوجه شدم مواردی هستند که ساختار درخت را بهم میریزند. به عنوان مثال برنج هم زیر مجموعه غلات بود و هم زیر مجموعه نشاسته بود. به همین دلیل متوجه شدم ساختار دادگان یک گراف جهت دار بدون دور است.
لحاظ نگرفتن همین پارامتر سبب بازنگری مجدد در همه زبانها و تکنولوژی های انتخابی برای پیاده سازی شد. چراکه در ابتدا تصمیم بر استفاده از PHP و MySQL به عنوان زبان و پایگاه داده شده بود. MySQL یک پایگاه داده RDBMS ای بود. مبنای این نوع پایگاهدادهها نظریه مجموعههاست که آقای کاد آن را بیان کرد. طبق ذات این نوع پایگاه داده ها ارتباطات شبیه سازی میشوند و دادهها به صورت Entity دیده می شوند. برای همین منظور باید نگاشتی انجام میشد. من به عنوان معمار نرم افزار به بررسی تمام حالتهای نگاشت در پایگاه داده RDBMS شدم. برخی نگاشتها سرعت خواندن بالایی داشتند و در عوض سرعت نوشتن آن ها پایین بود و برخی برعکس. در این وضعیت باید تصمیمی گرفته میشد و از آنجاییکه نوشتن و درج در این پروژه نرخ سالانه داشت من تمام توجهام را روی بالابردن سرعت خواندن کردم و از مدلی استفاده کردم که برای درج در پایگاه داده از پیمایش درخت استفاده میکرد. به هر نود یک عدد در راست آن و یک عدد در چپ آن اختصاص داده می شد. تفاضل دو عدد راست و چپ و باقی مانده صحیح آن بر دو تعداد فرزندان را بر میگرداند. بنابرین در برخی عملیات order ای برابر یک داشتیم. اگرچه در موارد درج داده لود سنگینی را متحمل میشدیم.
مشکل واژهای مانند “برنج” در این ساختار آن بود که نمیتوانستیم طبق این مدل یک نود را زیر مجموعه دو پدر قرار دهیم. بنابرین تمام تلاش دو ماهه بهم ریخت و مجدد دست به کار شدم. پس از تحقیقات کافی به این نتیجه رسیدم که مدل RDBMS نمیتواند مدل خوبی برای این قبیل پروژه ها باشد. پس به سمت NoSQL ها رفتم. اگرچه هیچکدام از اعضای تیم دانشی از این مدل دیتابیس ها نداشتند اما به بررسی این مورد پرداختم. درنهایت پایگاه دادهای با ماهیت کاملا گرافی به نام Neo4j انتخاب شد. این پایگاه داده بر خلاف RDBMS ها بر اساس نظریه گراف تعریف شده بود. ارتباطات در این پایگاه داده جداگانه تعریف میشدند. زبان استفاده شده در این پایگاه داده نیز cypher نام دارد. در زمان توسعه از نسخه ۲ آن استفاده شد. به دلیل نبود دانش فنی خود با مطالعه مراجع انگلیسی آن زبان سایفر را فراگرفته و دادگان ImageNet را به طور کامل بر روی این دیتا بیس پیاده کردم.
بسط پذیری با کلمات فارسی
در فاز دوم تحقیق باید به این سوال جواب داده میشد. چطور میتوان دادگان ImageNet را با استفاده از کلمات فارسی بسط داد. برای این قسمت پروژه FarsNet مرجع کار قرار گرفت. فارس نت مشابه تصویر نت یک پروژه بومی سازی شده از مدل انگلیسی زبان خود به نام WordNet بود که توسط دانشگاه پرینستون اولین بار اجرا شده بود. پروژه فارس نت که در سال ۱۳۹۴ دو ورژن از آن گذشته بود به قدری دارای مشکل بود که نمیشد از آن استفاده کرد. اگرچه در پروژه تصویر نت قید شده بود باید از دادگان فارس نت استفاده شود ولی متاسفانه در یک گزارش که در آن سال تهیه کرده و برای مدیر گروه ارسال کردم این پروژه را بخاطر نقص های فراوان نمیتوانستیم به عنوان مرجع برای ساخت پروژه تصویر نت استفاده کرد. بنابرین تصمیم گرفته شد که کلمات ImageNet را که شامل ۳۳ هزار گروه کلمه میشد را ترجمه و استفاده کرد.
فاز پیاده سازی
در فاز پیاده سازی از پایگاه داده گرافی Neo4j به عنوان دیتابیس استفاده شد و Node.js به عنوان بک سایت مورد استفاده قرار گرفت. زبان HTML, CSS و جاوااسکریپت نیز به عنوان قسمت طراحی وب استفاده شد. پیاده سازی شامل موارد زیر شد.
- دانلود ۱۴ میلیون تصویر: حدود ۵۰ درصد تصاویر به دلیل فیترینگ قابل دسترسی نبود و تعداد نامشخصی از تصاویر نیز دیگر در دسترس نبودند. بنابرین برای دانلود ابتدا تصاویر فیلتر را جدا کردیم. سپس با استفاده از Bash Scripting در سیستم عانل Ubuntu مشغول دانلود در دیتاسنتر پژوهشگاه فضای مجازی شدیم. برای ادامه موارد نیز از یک سرور دیگر با وی پی ان استفاده شد. برنامه نوشته شده به صورت پارالل کار میکرد.
- طراحی و نوشتن RestAPI : جهت اتصال عاملهای هوشمند نیازمند API ها بودیم. این API ها باید به گونه ای طراحی میشدند که بار سنگینی به سرور وارد نکنند.
- ترجمه ۳۳ هزار گروه کلمه: ترجمه نیز مشکل دیگری بود که برای آن از مترجمهای آنلاین استفاده شد که به صورت خودکار دادگان را ترجمه میکرد.
- انتقال ۳۳ هزار گروه کلمه به پایگاه داده: برای این منظور با استفاده از Regular Expression دادگان فرمت cypher گرفته تا بتوان در دیتا بیس نوشته شوند.
- اصلاح و یافتن ایرادات فارس نت
- اتصال تصاویر به گروه کلمات
بومی سازی با استفاده از دادگان فارسی
در این مقطع ابتدا متوجه شدیم بسیاری از کلمات در خود پروژه ImageNet موجود است. به عنوان مثال واژه سجاده و عبا که واژگان متناسب با فرهنگ اسلامی بودند و یا مفاهیمی نظیر نوروز و هفت سین نیز در ساختار دادگان ImageNet موجود بود. اما تعداد اندکی باید اضافه میشد. به عنوان مثال خورشتهایی موجود بود که در این ساختار نبودند. بنابرین باید ابتدا این موارد یافت میشدند و بعد از بررسی و صحت اینکه در دادگان فعلی موجود نیست توسط رباتی که تیم پارسی جو (موتور جستجوی ملی) در اختیارمان قرار داده بود از گوگل عکسها دانلود و اعتبار تصاویر توسط روش جمع سپاری crowdsourcing بررسی میشدند.
در نهایت پروژه پس از نهایت یکسال تحقیق و توسعه در پژوهشگاه فضای مجازی به اتمام رسید. نقش من در ایفای این پروژه معماری نرمافزار، طراح وب و مدیر پایگاه داده گرافی بود.
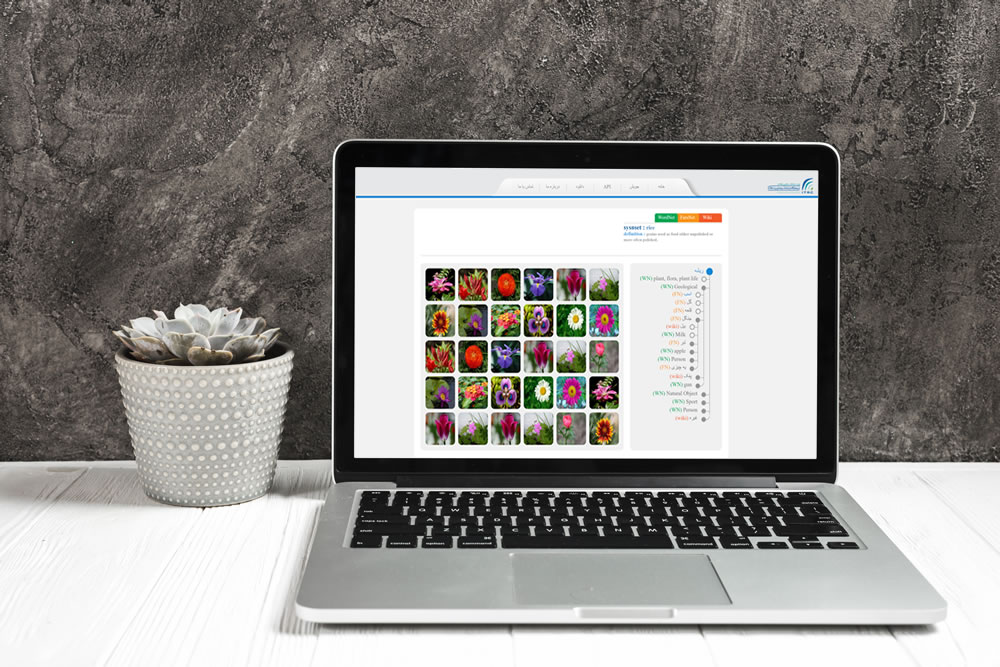
توضیحات
پژوهشگاه فضای مجازی (مرکز تحقیقات مخابرات ایران)
آبان 94 - مرداد 95
پروژه شاخص ملی